
Whenever we build ECS clusters, the topic of ECS scaling seems to be the most confusing for our customers. We wrote this blog post to explain two basic concepts you need to know about: scaling ec2 instances and scaling containers.
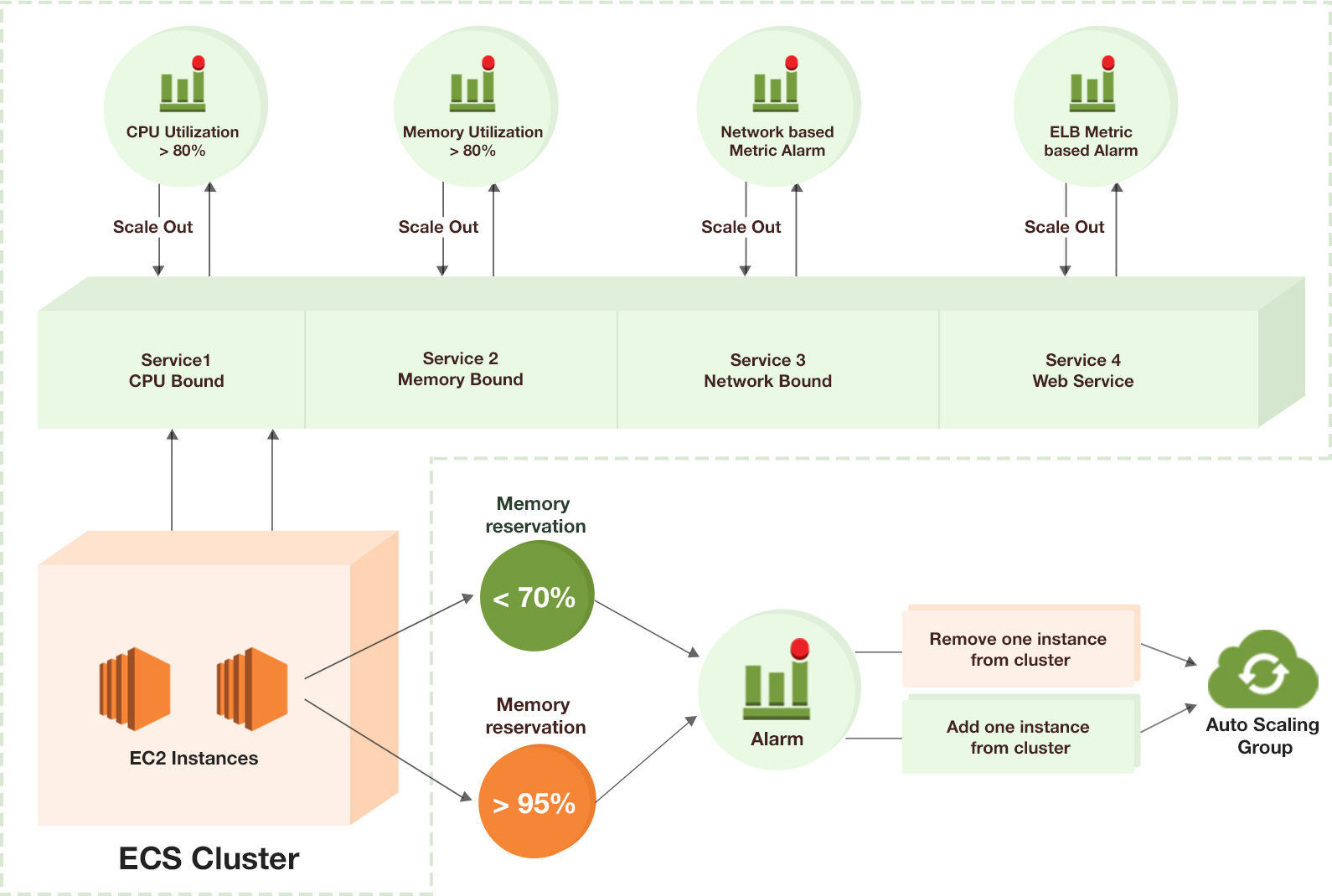
Scaling EC2 instances
As illustrated in the image above, you should configure your autoscaling to auto-scale based on the reserved capacity. Doing so will enable ECS to spin up new instances when you run out of memory.
The same logic can be applied to Spot Fleet with Auto Scaling
https://aws.amazon.com/blogs/aws/new-auto-scaling-for-ec2-spot-fleets/
If you look at this CloudFormation link, you’ll notice that we’re scaling up EC2 instances based on MemoryReservation. We reserve additional memory each time we launch a container and use auto scaling to launch additional instances once we run out of capacity to launch additional instances.
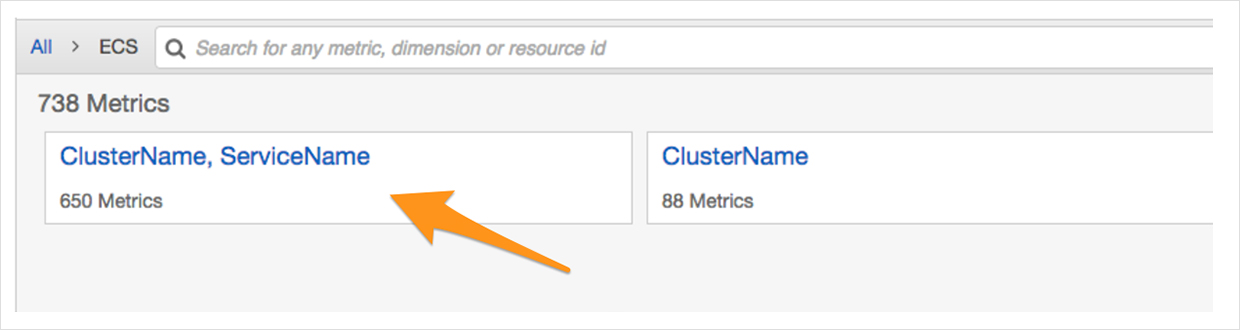
You can refer to the reserved metrics in CloudWatch and click on the ClusterName.
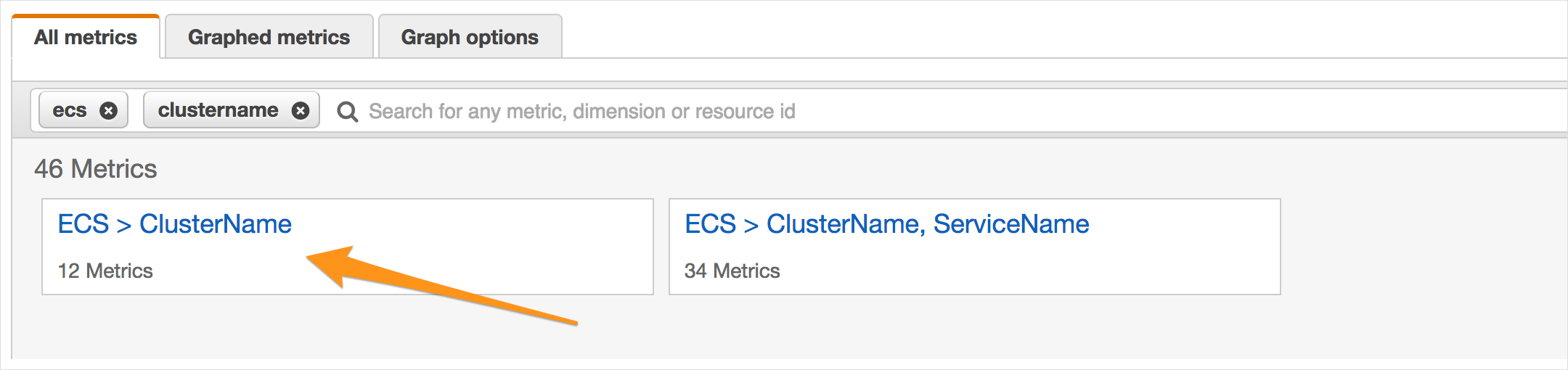
In the example below, we have reserved 65% of capacity already. If you continue to launch more containers, they will fail to launch due to a lack of capacity.
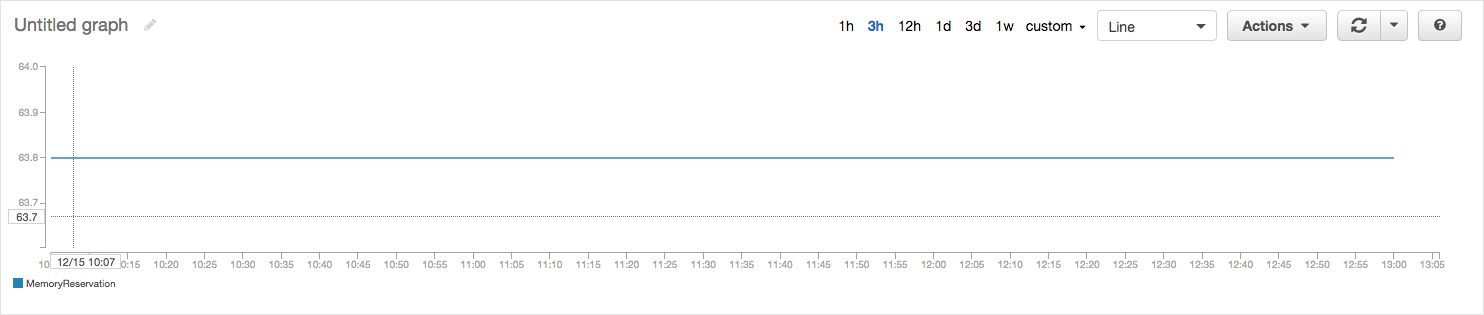
Scaling ECS services
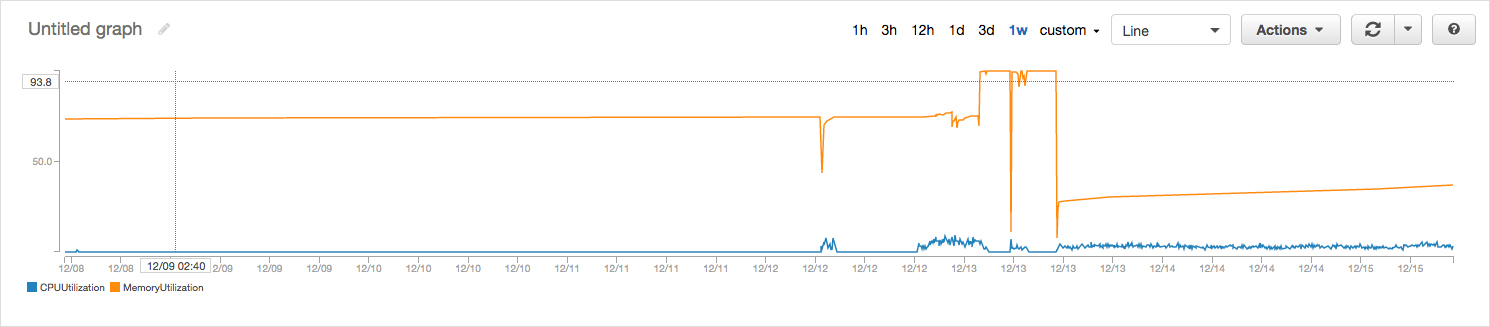
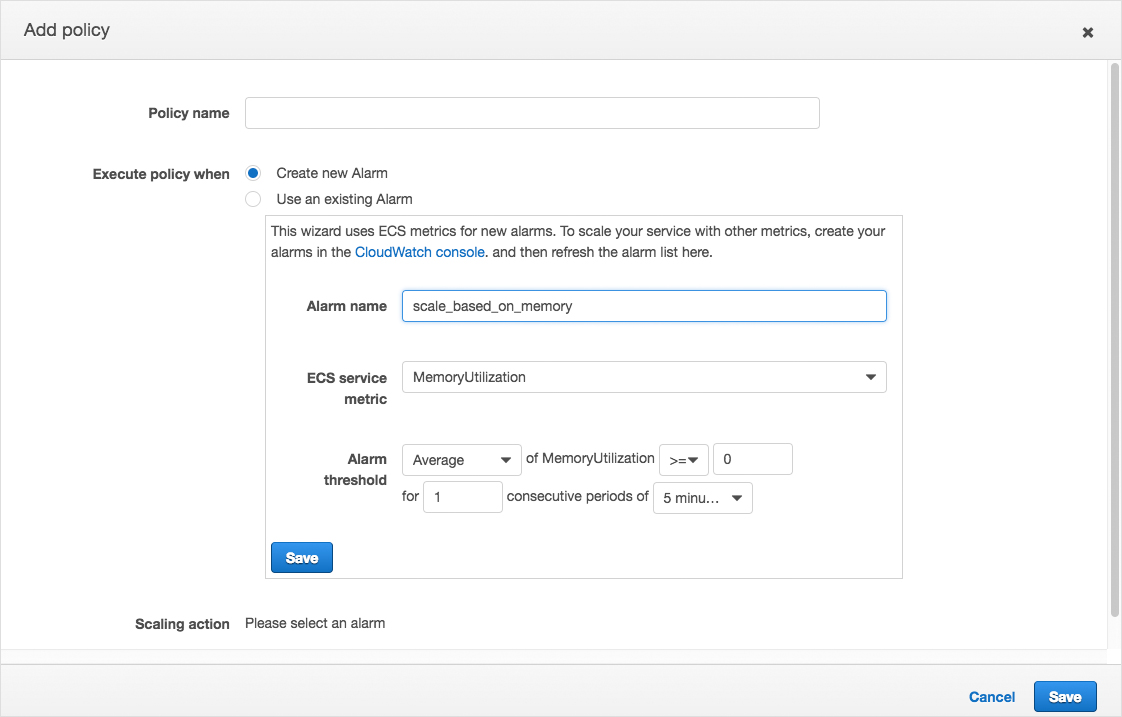
You should always keep an eye on the utilization of memory and CPU whenever you use an ECS console. Memory utilization is a measurement of how much memory is being used by containers. You can launch additional containers if you run out of memory.
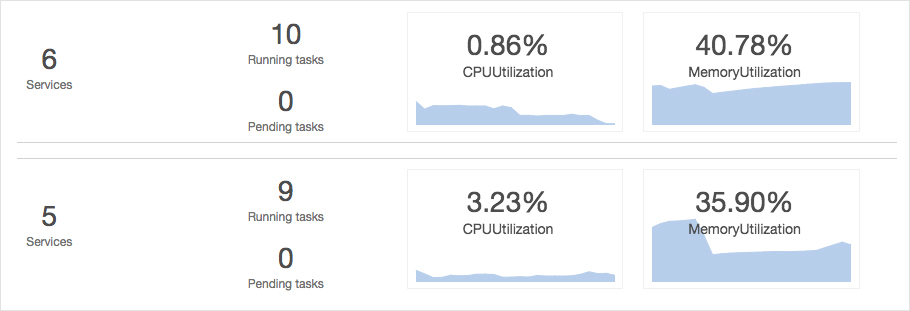
You must also scale Docker containers according to memory utilization, CPU utilization, and other relevant utilization metrics. You can launch additional containers if you run out of memory.
Here is an example of memory utilization for a service running on ECS.
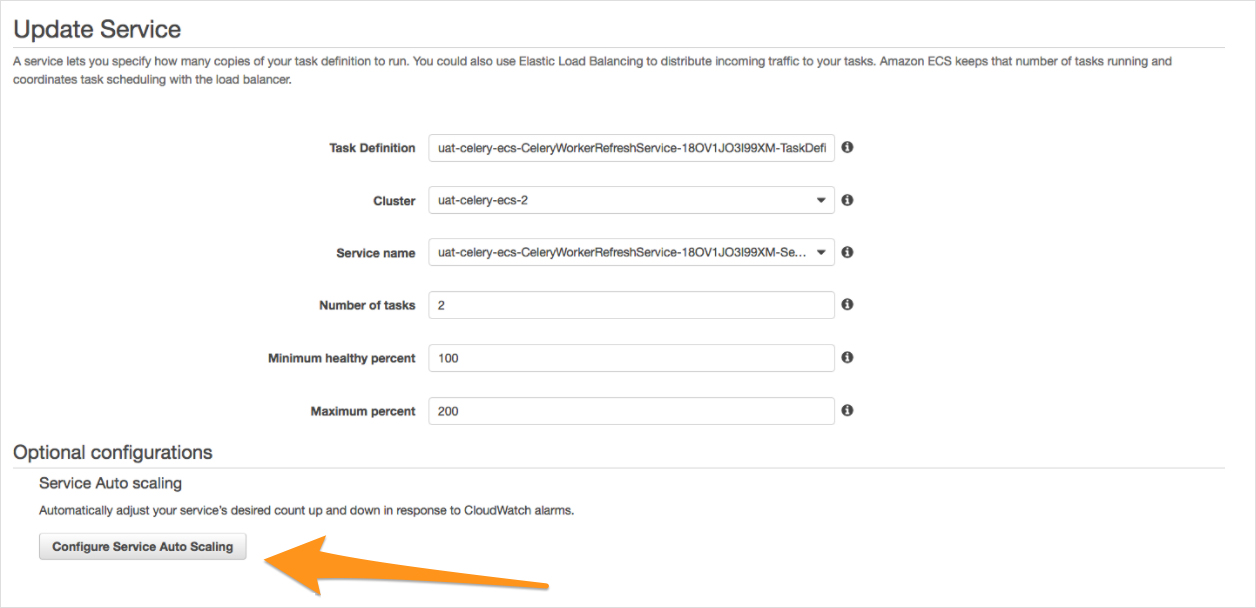
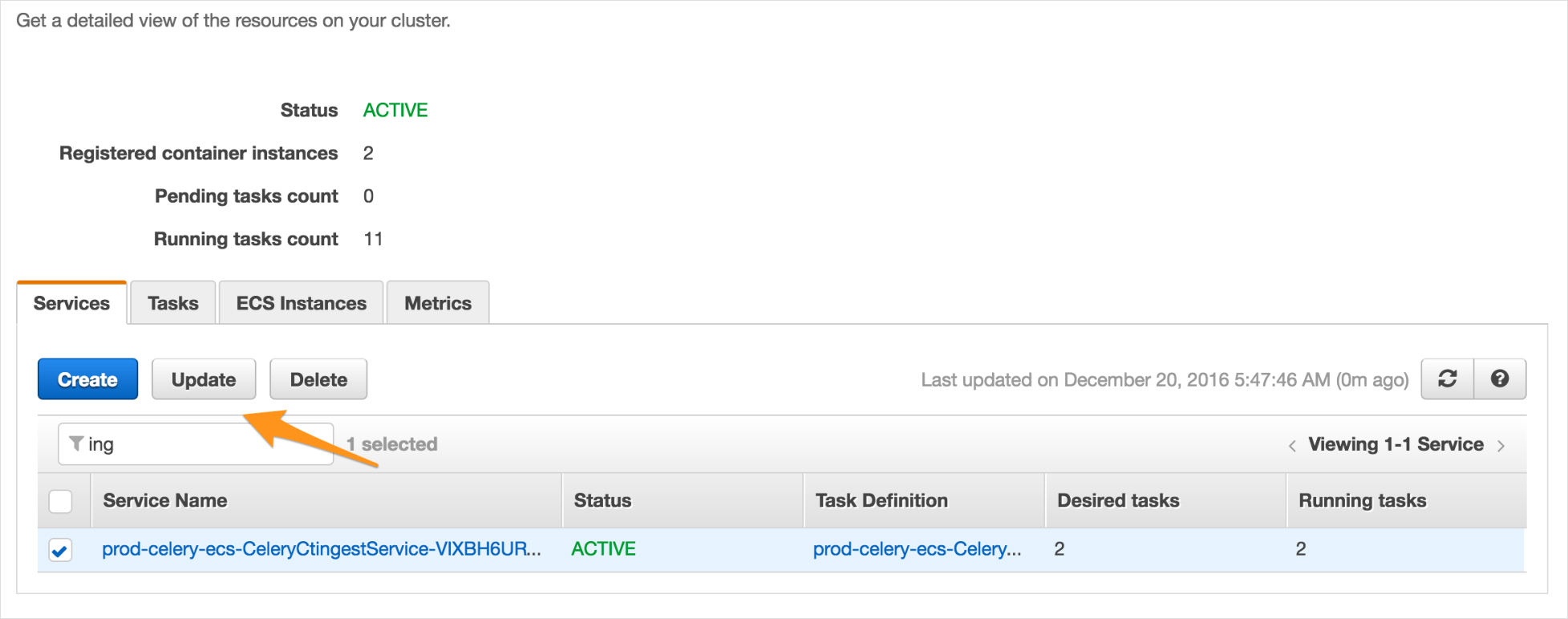
We mostly configure auto-scaling using Terraform or CloudFormation, but you can also configure service scaling from the AWS console. All you have to do is select a service running in the cluster and click on update.
We would love to learn how you are using ECS autoscaling. Please leave a comment with any tips.


