
From big organizations to mom and pop shops, everyone is moving to and is affected by the cloud, especially when disaster strikes causing downtime. Downtime is not an option for big organizations or for mom and pop shops. Whether it’s a ransomware attack, a power outage, flood or simply human mistakes, unpredictable events occur. The best approach you can have is to BE PREPARED. This is precisely the situation we found ourselves in when we began work for one of our clients. After first performing an AWS Well-Architected Framework Review, we found that they lacked a resilient Disaster Recovery (DR) program.
Of course they wanted the problem fixed. They wanted us to, “Take our EC2 instance, and if it goes down, bring up a new instance that conforms to our RTO/RPO requirements.” Sounds simple, right? Except that they added one caveat, there could only be a minimal cost increase, which meant no blue/green deployment. A blue/green deployment is an application release model that gradually transfers user traffic from a previous version of an app or microservice to a nearly identical new release — both of which are running in production, which also substantially increases the pricing. UGH!
Now the official and documented way to fulfill our client’s Recovery Time Objective/Recovery Point Objective (RTO/RPO) with the software currently running on their Amazon EC2 instance would be to either:
- Create a primary/replica situation, and implement a shift for whenever the primary might go down, or,
- Set up an Amazon Relational Database Service (Amazon RDS) database that would host the user information, so whenever a new instance was brought up through AWS Auto Scaling, it would be possible to use the user data script to pull the user information and populate the software.
Both of those are elegant solutions. However, both solutions clashed with the client’s cost requirements. Running an Amazon RDS database while also running an additional Amazon EC2 instance would certainly increase the costs over their allowable “minimal” amount. On top of that, adding an extra component like Amazon RDS adds another point of failure. For example, suppose you run into an Amazon EC2 downtime, and while the user data executes, a concurrent Amazon RDS downtime event joins the party. You would then have an empty block running the software without the user information because Amazon RDS was unavailable during the Disaster Recovery attempt. Did I say, UGH!
Thankfully, we had some good fortune. AWS had recently upgraded its Amazon Data Lifecycle Manager (Amazon DLM) service. This upgrade gave us an idea that we hoped would lead to a Proof of Concept (PoC) breakthrough.
Amazon DLM now provides a way to use AWS managed resources to create snapshots automatically, and they fulfill all RTO/RPO requirements. Before this upgrade, investing in third-party tools, or creating custom scripts to leverage a bunch of moving parts to automatically create Amazon EBS snapshots was inescapable. These practices often led to multiple points of failure because they were customizations with complex solutions. Think of trying to build a house of cards, floor to ceiling, windows open, on a windy day!
Thanks to Amazon DLM, the need for sophisticated and customized automation scripts to manage Amazon EBS snapshots was eliminated. Amazon DLM lets you create, manage, and delete Amazon EBS snapshots in a simple, automated way, based on Amazon EBS volume tags or Amazon EC2 instances. This reduces the operational complexity of managing Amazon EBS snapshots, thereby saving time and money. Even better is that Amazon DLM is free to use, and it is available in all AWS Regions.
For our use case, we created a custom Amazon DLM policy that would create a snapshot every Friday evening. This process was implemented at the end of the workweek, so we would always have a functional copy of all the users who were added during the week. Then the policy would pick up the instances that had the tags in the DR setup. In that way, we could do a targeted DR exercise on only the instances we wanted to include in the process.
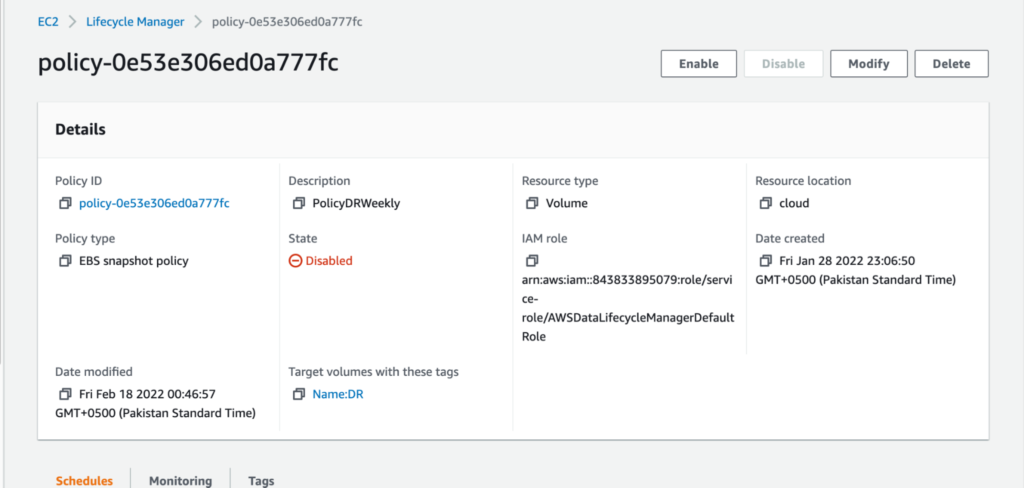
The next part is setting schedules based on the RTO/RPO requirement:
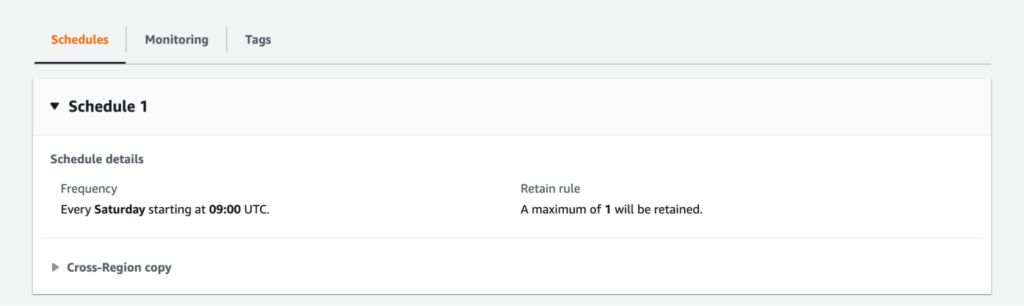
Amazon DLM allows you to have a retention policy. You can keep copies for a desired time or have a desired number of copies. Since we only wanted to have the single most recent copy, we went with the above. Amazon DLM also allows you to have both cross-Region and cross-account availability, which can really help with DR requirements that are too complex for custom solutions.
Once the Snapshot policy is up, all that is left is to set up monitoring on the target instance for any service downgrade. We accomplished that with an Event Rule that looked for state changes on the instance, which triggered an AWS Lambda instance in case it went down.
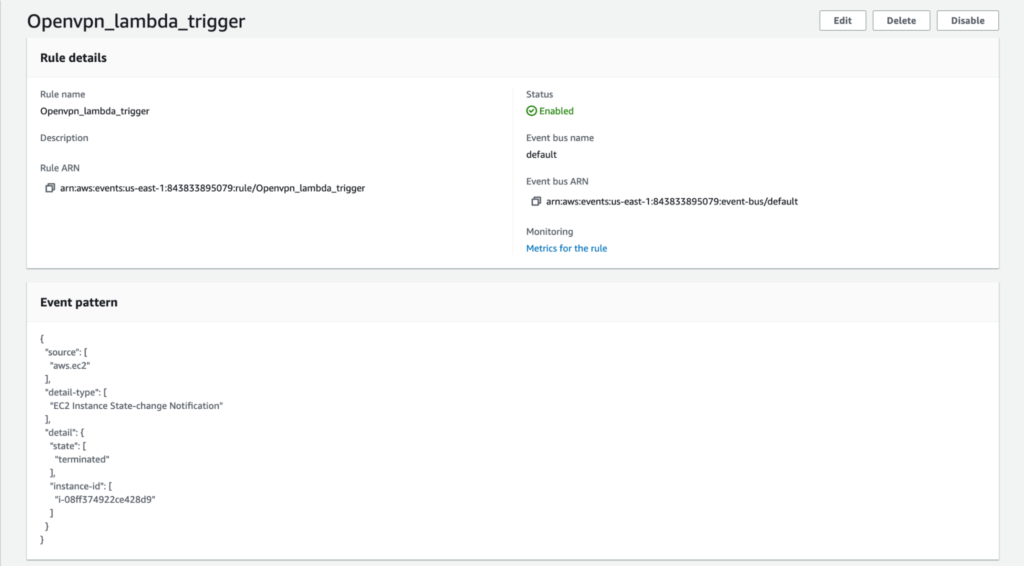
Should the instance go down, the Amazon EventBridge will automatically trigger a Lambda function that has the latest copy of the snapshot and will thus create a new instance.
So, the workload only works when there is an instance in the process of downgrading, or it terminates, thus reducing the cost to the utmost lowest. The pieces of the workload are also cost-effective because Amazon DLM is free to use, and you are only charged for the resources used, and the Lambda function will only be executed in case of a disruption.
As engineers, and based on our experience with Amazon DLM, we are confident that Amazon DLM will be a valuable and cost-effective tool when used for Disaster Recovery in conjunction with Amazon EC2 instances. Amazon DLM could be a factor in the elimination of custom code dependencies, and create a highly available, AWS-managed way to handle backups for everybody from big business organizations to mom and pop shops.
Need help with big data or disaster recovery initiatives? We’ve got the experience, AWS data and analytics knowledge and credentials, plus our research initiatives, to help you plan and execute your strategy.


