
Here at nClouds, many of our clients are fast-growth, data-intensive startups and growth-stage companies. They often ask for our help to optimize their data preparation time and costs, and deliver additional value to their customers. Sound familiar?
In such a case, I recommend a solution using AWS Glue and Amazon Athena to more easily structure and load the data for analytics, saving data preparation time. What’s exciting about AWS Glue is that it can get data from a dynamic DataFrame. With AWS Glue DynamicFrame, each record is self-describing, so no schema is required initially. A schema on-the-fly is computed when necessary, and schema inconsistencies are encoded using a choice (or union) type.
The following is an example of how I implemented such a solution with one of our clients, running a Spark job using AWS Glue while taking performance precautions for successful job execution, minimizing total job run time and data shuffling.
Customer Use Case
Our client, an innovative provider of cyber analytics to the insurance industry, sought expanded use of their data to provide additional value to their customers. They selected nClouds to help them based on our prior work with them and our AWS technical expertise in data and analytics.
We collaborated to implement a solution designed to ingest large amounts of external data, push it into relational structures, and make immediate use of it without requiring a lot of administration bandwidth to create new Amazon EMR clusters each time processing is needed.
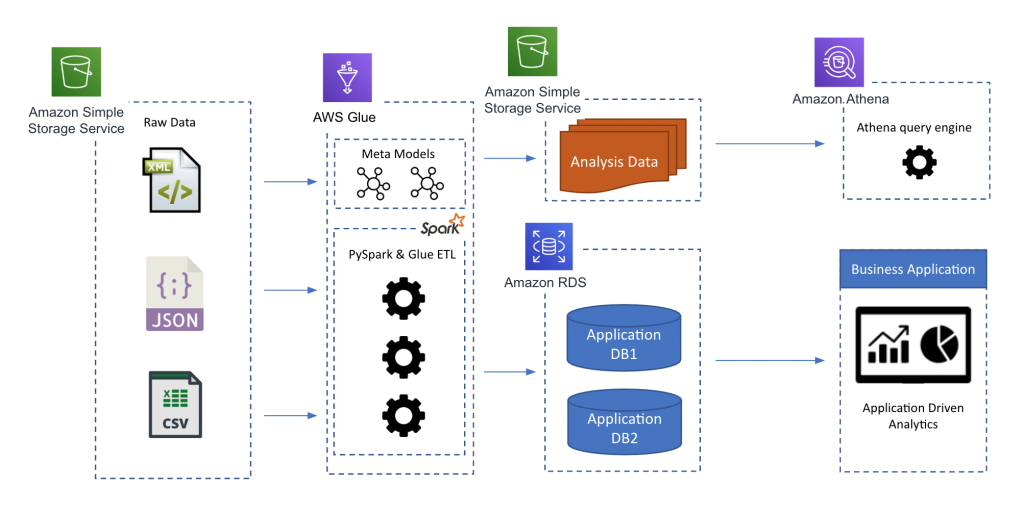
Here is the architecture we created using AWS Glue .9, Apache Spark 2.2, and Python 3:
Figure 1:
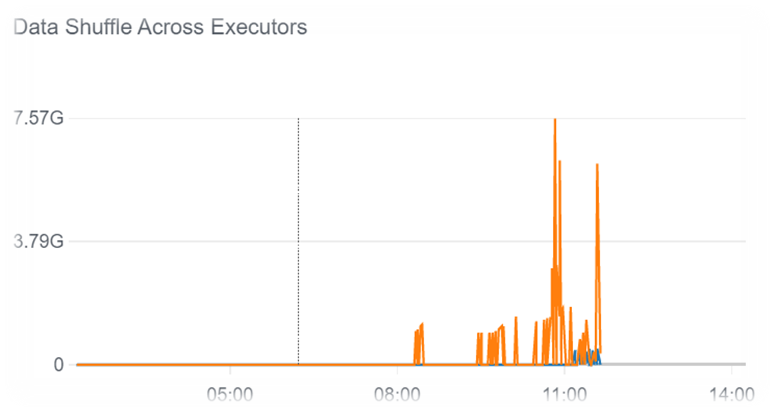
When running our jobs for the first time, we typically experienced Out of Memory issues. This was due to one or more nodes running out of memory due to the shuffling of data between nodes. You can see this in Figure 2. There is major shuffling going on across the nodes. Notice the blue peaks in this chart.
Figure 2:

This issue is sometimes band-aided by adding more memory in a typical Spark environment. In AWS Glue, you can add only more data processing units (DPUs) which does not increase memory on any one node but creates more nodes available for processing. To achieve maximum use of all DPUs allocated, I recommend the following steps:
- To accelerate data analytics, run job execution with broadcast variables (for the small datasets in use for outer joins), repartition (at twice the size of the Spark cluster executor cores), and repartition (half the size of repartition number).Repartition the dataset before the join or union operation. Repartitioning can increase or decrease the number of partitions in a DataFrame. It enables shuffle persistence and tunes the transformation.In our customer use case, this best practice resulted in a successful execution in 9 hours, 29 minutes – a 4-hour reduction in job time.By repartitioning our customer’s DataFrame to double the size of available cores, shuffle reads were negligible (shown in blue in Figure 3), and shuffle writes were a reasonable size, i.e., a maximum of 7.57G (shown in orange in Figure 3). You can see how this compares to Figure 2. The blue peaks showing shuffle reads in Figure 2 are spiking at over 13GB while in Figure 3 they are reduced to less than 1GB.Figure 3:
- When processing a large quantity of data as in this case, save time and memory by using coalesce(1) to reduce the number of partitions in a DataFrame before writing to an Amazon Simple Storage Service (Amazon S3) bucket or an AWS Glue DynamicFrame.In our customer use case, this best practice resulted in the memory profile shown in Figure 4.Figure 4:
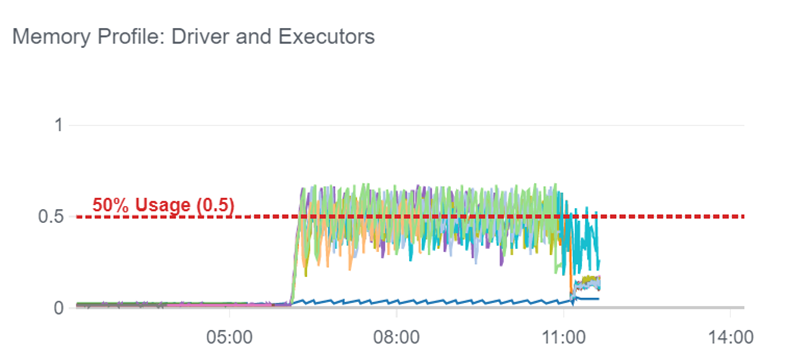 The memory profile shown in Figure 4 is optimal where each node is utilized similarly. So now adding nodes will reduce run time in proportion to the number of nodes added (while that is not the case in Figure 2). What we don’t want to see are any nodes that aren’t being leveraged and some nodes taking on the brunt of the memory load.
The memory profile shown in Figure 4 is optimal where each node is utilized similarly. So now adding nodes will reduce run time in proportion to the number of nodes added (while that is not the case in Figure 2). What we don’t want to see are any nodes that aren’t being leveraged and some nodes taking on the brunt of the memory load.
In conclusion:
By using AWS Glue, you can:
- Accelerate data analytics. Its automation makes data immediately searchable, queryable, and available for ETL (extract, transform, and load).
- Reduce data prep time. It takes datasets in different formats and converts them into a single, query-optimized format that can be consumed quickly by various analytical tools.
- Save costs. Pay for the time your ETL job takes to run – an hourly rate based on the number of data processing units (DPUs) used. There are no resources to manage, no upfront costs, no charges for startup or shutdown time.
Need help with data analytics on AWS? The nClouds team is here to help with that and all your AWS infrastructure requirements.


