
Here at nClouds, we often work with fast-growth clients that require analytics of real-time streaming data. They need a modern data and analytics architecture that:
Enhances efficiency and performance by:
- Processing data at high speed.
- Scaling automatically to maintain consistently high performance.
- Starting as many instances as needed without lengthy deployment and configuration delays.
- Storing objects in cache that are read frequently, to improve latency and throughput.
Optimizes operational costs by:
- Using data and analytics services on a pay-as-you-go basis.
- Supporting fast, inexpensive, and replayable reads and writes in the storage layer.
- Batching, compressing, partitioning, and transforming data before loading it to minimize the amount of storage used.
- Notifying the storage layer to delete data that is no longer needed once computations have run in the processing layer.
Sound familiar?
Following is an example of how I implemented such a solution with one of our clients, to cut operational costs by more than 50% (actually, by an impressive 72% in this case), and improve the efficiency and performance of their data and analytics system.
Customer Use Case
Our client, a fast-growth, AI-powered mediatech that uses streaming social media, wanted to reduce their data analytics costs without sacrificing performance. They selected nClouds to help them based on the findings of an AWS Well-Architected Review we did with them and our AWS technical expertise in data and analytics.
The client’s original architecture was a traditional Cloudera data and analytics solution using Hadoop and block storage. We collaborated with them to implement a modern, simplified, cloud-native Apache Spark data and analytics architecture — using Amazon Athena for access and Amazon Simple Storage Service (Amazon S3) object storage — designed to reduce operational costs and improve efficiency and performance based on best practices.
Why Apache Spark instead of Hadoop? And why Amazon S3 object storage instead of block storage?
- Apache Spark is ideal for handling real-time data (the streaming social media data in this case), with low latency and interactive data processing. Hadoop is designed to handle batch processing, has higher latency, and cannot process data interactively.
- Object storage can search metadata faster than block storage — particularly crucial for rapid analytics of streaming data because scalability is required to ingest and transform unstructured live data feeds for real-time analytics. And, Amazon S3 object storage is less expensive than Hadoop Distributed File System (HDFS) block storage.
The client was interested in moving to a fully managed Platform-as-a-Service (PaaS) model from an Infrastructure-as-a-Service (IaaS) model, and going serverless (i.e., a Function as a Service, or FaaS, model).
Note: FaaS is a simple, event-based architecture that triggers the execution of a function, where the cost is based on usage (you’re charged only for the resources consumed when the code runs). When FaaS is connected to PaaS, as in this case, we are combining functions with microservices.
Costs were optimized by using the following AWS pay-as-you-go services:
| Amazon API Gateway | Pay only when your APIs are in use. |
| Amazon Athena | Pay only for the queries you run, based on the amount of data scanned by each query. Significant cost savings and performance gains can be attained by compressing, partitioning, or converting your data to a columnar format, reducing the amount of data that Athena needs to scan to execute a query. |
| Amazon Comprehend | Pay only for what you use, based on the amount of text processed monthly. |
| Amazon DynamoDB | Pay for reading, writing, and storing data in your DynamoDB tables, along with any optional features you choose to enable. There are two modes:
|
| Amazon ElastiCache | Get started with this managed caching service for free – the AWS Free Usage tier includes 750 hours per month of a t1.micro or t2.micro node. After that, pay only for what you use:
|
| Amazon Elasticsearch Service | Pay only for what you use – instance hours, Amazon EBS storage (if you choose this option), and data transfer. |
| Amazon Kinesis Data Firehose | Pay only for the volume of data you ingest into the service and, if applicable, for data format conversion. It can save on storage costs by batching, compressing, and transforming data before loading it to minimize the amount of storage used at the destination. |
| Amazon Simple Storage Service (Amazon S3) | Pay only for what you use. AWS charges less where their costs are less, based on the location of your S3 bucket. |
| AWS Fargate | Pay only for the vCPU and memory resources that your containerized application uses. |
| AWS Glue | Pay an hourly rate, billed by the second, for crawlers (discovering data) and ETL jobs (processing and loading data). If you provision a development endpoint to interactively develop your ETL code, pay an hourly rate, billed per second. For the AWS Glue Data Catalog, pay a monthly fee for storing and accessing the metadata – the first million objects stored are free, and the first million accesses are free. |
| AWS Lambda | Pay only for what you use, based on the number of requests for your functions and the time it takes for your code to execute. |
Below is the architecture I created to perform real-time data analytics on streaming social media feeds.
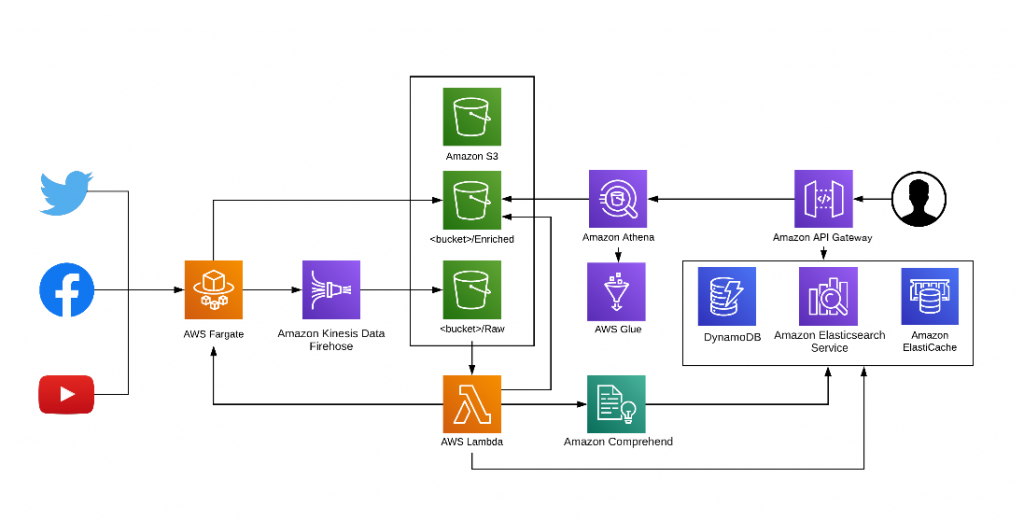
Here is how this architecture functions:
- We’re using AWS Fargate, a compute engine for Amazon Elastic Container Service (Amazon ECS), that enables you to run containers without having to manage servers or clusters. An AWS Fargate job runs to pull social media feeds (from Twitter, Facebook, and YouTube) and delivers that streaming data to Amazon Kinesis Data Firehose (a fully managed service that enables near real-time analytics and insights). Amazon Kinesis Firehose captures, transforms, and loads the data into the Amazon S3 raw bucket.
- AWS Lambda is a serverless compute service that runs stateless code in response to events and automatically manages the underlying compute resources. It improves performance by:
- Scaling automatically to maintain consistently high performance as the frequency of events increases.
- Starting as many instances as needed without lengthy deployment and configuration delays.
In our architecture for this client, when AWS Lambda kicks in, it calls Amazon Comprehend – a machine learning-powered service that uses natural language processing (NLP) to find insights and relationships in unstructured data – and other processes to enrich the data. To power the User Interface (UI), it writes to the Amazon S3 Enriched bucket.
- Next, an AWS Glue job gets triggered. AWS Glue is a fully managed extract, transform, and load (ETL) service that creates a data catalog and populates the Amazon Athena table(s). Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL.
- Updates are then made to:
- Amazon Elasticsearch Service, a fully managed service to deploy, secure, and operate Elasticsearch at scale with zero downtime.
- Amazon ElastiCache, which scales out, in, and up to meet fluctuating application demands – significantly improving latency and throughput by storing in cache the objects that are read frequently.
- An application based on React (a front-end web development tool) accesses Amazon DynamoDB (a key-value and document database) and Amazon ElastiCache (rather than Amazon Athena) to serve all real-time UI requests. For historical queries, an asynchronous request to Amazon S3 is made, and the UI is notified when the response is ready to be viewed or downloaded.
In conclusion:
If you need to perform real-time analytics of streaming data, want to reduce your data analytics costs without sacrificing performance, and are currently using a Cloudera-based architecture, consider shifting to an architecture based on AWS-native services. The use case described above is just one of many customers nClouds has partnered with that have realized the benefits of such a modern, simplified data analytics architecture:
- Operational costs reduced by more than 50%.
- Improved data analytics efficiency and performance.
If you want to read more about the related customer story, check out the case study with this AI innovator and mediatech.
Need help with data analytics on AWS? The nClouds team is here to help with that and all your AWS infrastructure requirements.


