

At nClouds, many of our 24/7 Support Services customers have some pretty aggressive Service Level Agreement (SLA) deadlines. So, we continuously search for strategies to help them separate the “signal from noise.” In this blog post, I’ll provide tips on the strategies we use to help our customers reduce alert fatigue and avoid recurring incidents.
Proper contextual monitoring
One of the essential functions of any alert is to give it the proper context. To save time and money, alerts should contain the correct name of a resource/service, its current state, the threshold that the resource crossed, any tags and associated logs, a link to the runbook, and a detailed graph/chart, if possible. This approach helps the team to more quickly understand the violation, and it directly reduces the efforts to resolve the incident.
For instance, let’s say a memory alert has been received without the proper context. Valuable time is wasted trying to figure out the “what” and “where” of the violation, delaying taking action on the alert.
Here is an example of how we set up memory alerts using Slack and Datadog at nClouds:
Alert configuration:
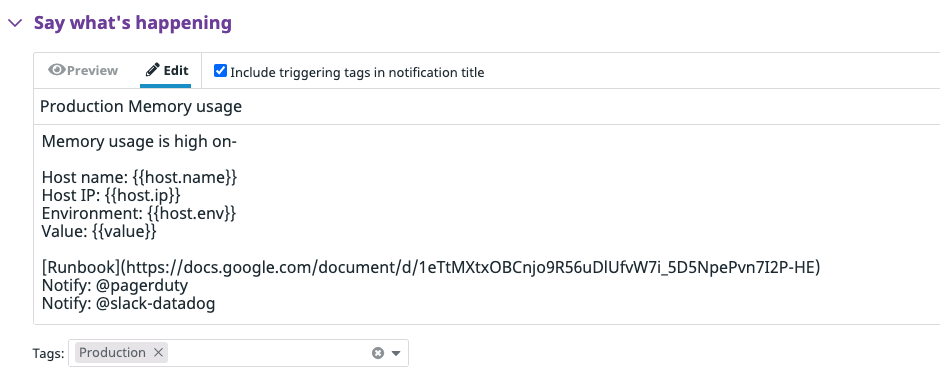
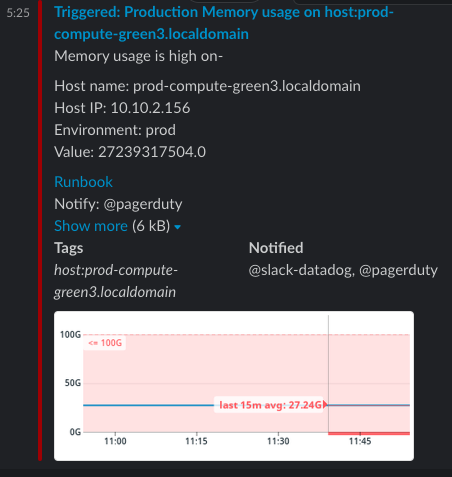
As an on-call engineer, this Slack alert gives me all the relevant information I need to begin resolving the issue.
Why it’s crucial to conduct root cause analysis (RCA) of recurring issues
No matter how tempting it may be, it’s never a good idea to ignore alerts. Alerts indicate problems, and most of the time, problems do not go away unless the root cause has been addressed and fixed. Far too often, alerts are ignored or put off until recurring incidents pile up and outages occur, eroding customer confidence.
For example, let’s say that a server crashes when the disk is full. If the engineer just removes some log files and restarts the service to make things work again without taking any further action, most likely the outage will happen again in the future.
That’s why it’s critical to implement a regularly scheduled RCA process. It’s the best way to learn from an incident, and it’s the best way to develop a strategy for reducing or eliminating future alerts.
A correctly conducted RCA provides complete, detailed documentation on an incident — the root cause, the actions taken to mitigate or resolve the issue, the business impact, and the actions taken to prevent reoccurrence (e.g., configuring the logrotate tool to manage log files created by system processes, or setting up a metrics forecast). It will significantly minimize the likelihood of the same incident happening in the future. And, should the worst-case scenario repeat itself, the requisite information will be available to help you resolve the incident much more quickly. RCA on outages are a must, but we also find tremendous value in doing RCA for noisy alerts. At nClouds, we conduct an internal RCA every week.
Datadog is one of the tools we use to build real-time awareness of the status of our clients’ AWS environment, prevent many issues from ever occurring, and, when needed, step in to remediate incidents. Datadog provides a cool new Incident Management platform that is very helpful during the incident-handling process and postmortem.
Predictive monitoring
Not all alerts should be set to trigger on static thresholds. Rather than waking up at midnight to fight fires, we can use solutions powered by artificial intelligence (AI) to notify teams in advance before it becomes a real problem. Datadog’s metric forecasts for predictive monitoring are an excellent example of this approach. For instance, we can use it to notify about disk usage in advance before it fills up.
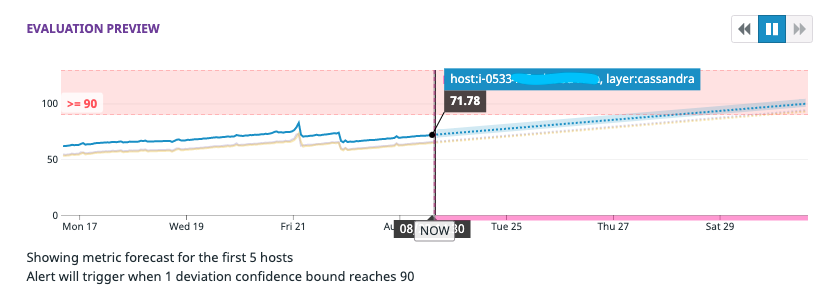
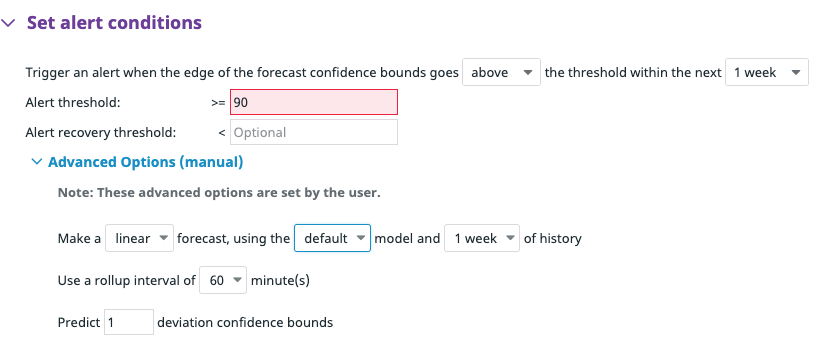
In the above example, the monitor is configured to trigger a week before the disk reaches 90% usage. We can also choose our strategy according to our use case. Datadog provides options to use Linear or Seasonal algorithms.
- Linear: For metrics that have steady trends but no repeating seasonal pattern.
- Seasonal: For metrics with repeating patterns.
Reporting and analytics
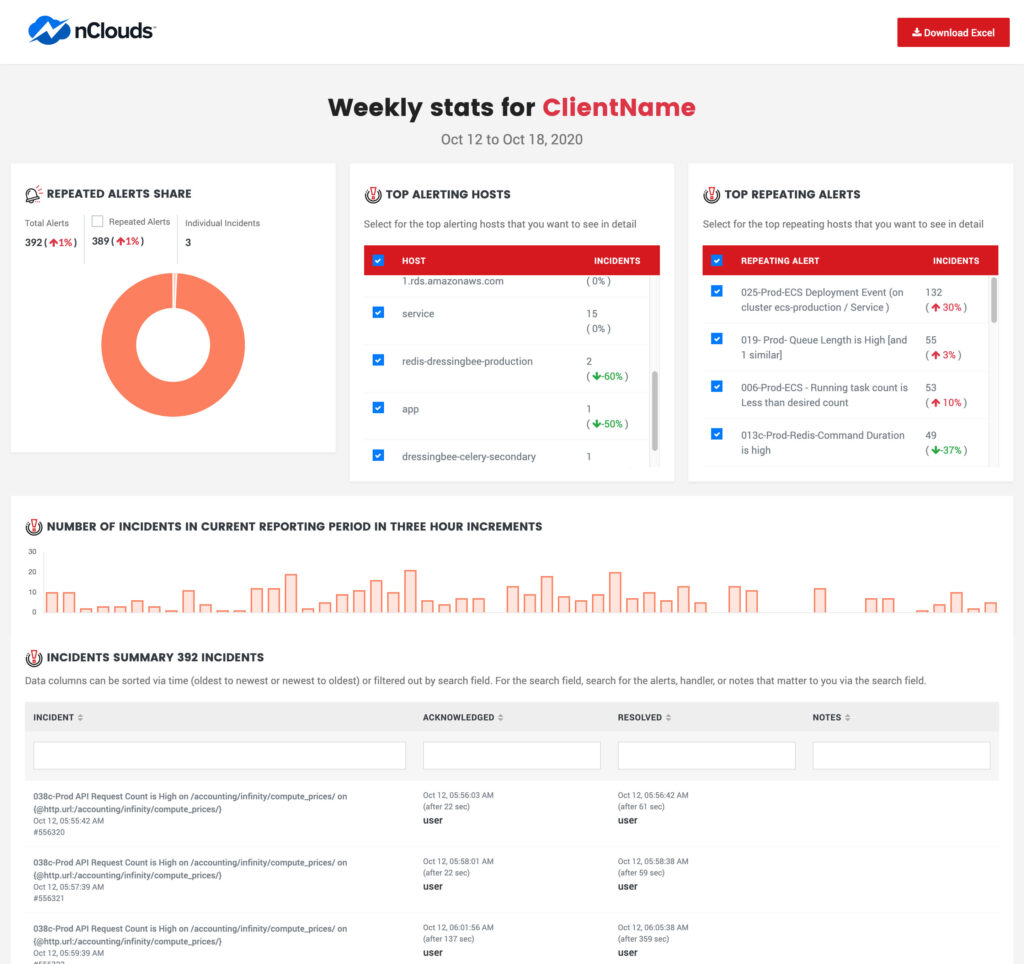
Alert fatigue is real, even at nClouds. Our process is to review alert reports weekly and retrieve feedback from our 24/7 Support Services team regarding recurring and noisy alerts. Then, we implement the necessary actions to ensure that incidents do not reoccur. We understand that a functional feedback loop is an essential supplement to our efforts to continuously improve our monitoring systems by fine-tuning or cleaning up monitors.
At nClouds, we generate a weekly report to pick up the top triggered hosts and alerts. We compare those reports with past reports to analyze our efforts and improvements.
In conclusion
Consider implementing best practices strategies to reduce alert fatigue and avoid recurring incidents — proper contextual monitoring, RCA of recurring issues, predictive monitoring, weekly review of alert reports, and a functional feedback loop on recurring and noisy alerts.
For additional tips on reducing alert fatigue, please take a look at my recent blog that features Datadog’s composite monitor feature, “How to aggregate monitoring alerts to reduce alert fatigue.”
Need help with meeting your AWS infrastructure support SLAs? Would you rather refocus your engineers on innovation instead of providing infrastructure support? The nClouds 24/7 Support Services team is here to help you maximize uptime and business continuity and achieve your AWS infrastructure support SLAs at a competitive rate.

